
Hi everyone, I’ll start with a bit of background. I’m Ben’s younger brother, Nick, and I was very keen to see how his software works. Other than mild short-sightedness, I do not think there is anything wrong with my eyes. Sitting in Ben’s office, I noticed a 3D magic eye picture on the wall, and…
When Unity UI Goes bad – The perils of DontDestroyOnLoad
This is quick note about a really obscure problem which can bite you quite hard in unity. If you switch between scene you may need to use DontDestroyOnLoad to keep certain objects hanging around during and after the transition. If, however, you have stored collections of scripts under empty game objects – and there should…
Lets laser cut some headsets!
Over at eyetracktive.org you can see the results of some early experiments in creating the world’s most affordable eye tracking headset. The idea is to make this compatible with off the shelf google cardboard headsets. One constantly underestimated problem, however, is that people have quite differently shaped heads, and eye positions. I find it obnoxious…
An afternoon with Marco Schätzing
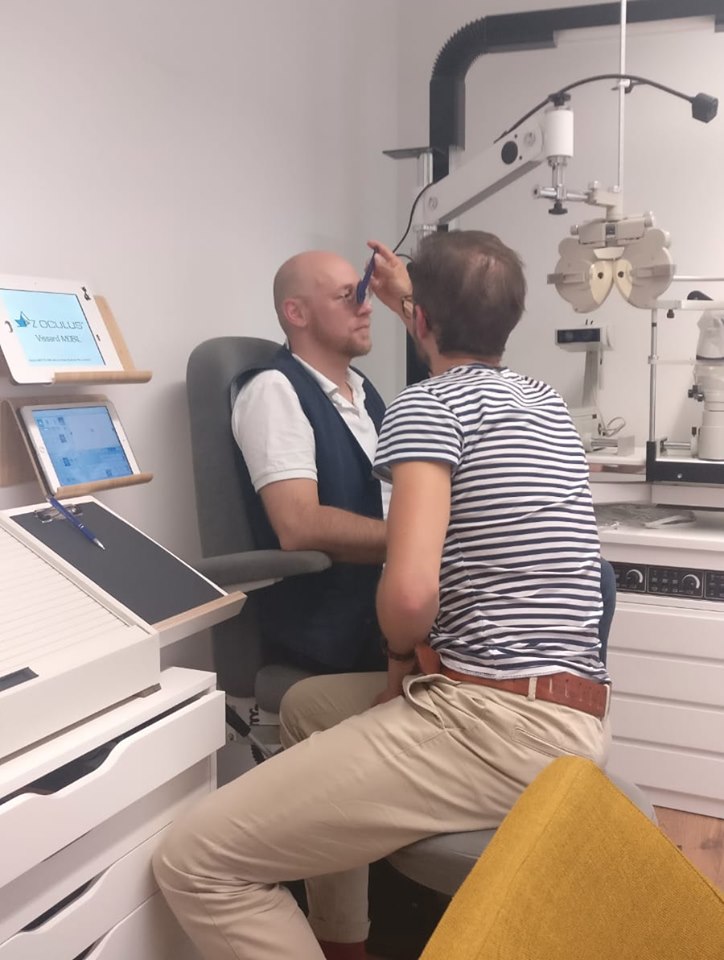
Hello there, Lukas here. I am a new member of eyeskills and today I decided to put out my first facebook post! Ben and I had the great chance to meet Marco Schätzing in his natural habitat. He is a studied optometrist and works as a visual trainer. Today, Marco showed us the “Maddox Test”…
Protected: Animating EyeSkills – Building bridges between Blender and Unity
There is no excerpt because this is a protected post.
Blender Outlining [SOLVED] – Cannot find Backface Culling option under Viewport Shading.
Helping people with Lazy Eye learn to use both eyes again requires a long term commitment on their part. That shouldn’t be a drag, so I am hoping to inject a little humour through two animated characters which accompany the participant on their journey, helping to motivate people to continue. A part of the look…
Notes on Using Blender 2.8
One thing I discovered when testing EyeSkills at the beginning, is that people who have a lazy eye often have a particular psychological relationship to the condition. They would like to understand and perhaps change it, but they have generally come to accept it as “inevitable” and found ways to compensate in everyday life. It…
Notes on Unity Animation
This wasn’t a bad starting point : https://www.youtube.com/watch?v=vPgS6RsLIjk It’s important to remember, when you’ve created a sprite, that you need to add a SpriteSkin. Sometimes it fails to automatically detect the bones in your sprite, but so far, that’s been simple to solve by making a few minor changes to the sprite, reapplying, and then the…
A general post on Unity Pain Points and Setup
Error After switching XR device to “cardboard”, any TrackedPoseDriver script which is active will have lost its connection (changes to its state make no noticeable changes to the scene). Solution Destroy the TPD before the device switch, then re-create and re-initialise it afterwards. Error [EGL] Unable to acquire context: EGL_BAD_ALLOC: EGL failed to allocate resources…
Eleksmaker A3 Laser Cutter
So, I’m still trying to get the Eleksmaker A3 laser cutter to work as I need. So far, I’ve come to the conclusion that the original version of GRBL installed on the cheap Arduino nano board the “Mana” board comes with, is just no good. I’ve flashed it to v1.1 : brew install avrdude avrdude…